kaggleやるよ何て名前をつけておいて1年半くらいkaggleやってませんでした。
その間何やってたかって言うとAI使ったWebサービスを作ろうとして挫折してを繰り返してました。
今のところ何の生産物も無いっていう悲惨な状況なんですけど、しょうもないノウハウ達は手に入れたのでせめてもの手向けとして公開しようかなと思う。
① 紙の領域検出
画像の中に含まれる領域を検出するメジャーな方法としてはCanny特徴量でエッジ検出+Hough変換で直線の検出っていう組み合わせがメジャーだと思います。
ただCanny特徴量は紙以外の物体が入っていたり紙面に色々描かれていたりすると、余分なエッジまでも検出しちゃってその後の工程が失敗しちゃう可能性があったりします。
 なので深層学習とかで都合よく検出できたりしないかなーって探していたら、偉大なDropboxが技術ブログを公開してました。
なので深層学習とかで都合よく検出できたりしないかなーって探していたら、偉大なDropboxが技術ブログを公開してました。
なので深層学習とかで都合よく検出できたりしないかなーって探していたら、偉大なDropboxが技術ブログを公開してました。今のChromeには素晴らしい翻訳機能があるので紹介するまでもないとは思いますが、彼らがやってることとしては、
- 何らかの深層学習の方法(各ピクセルのエッジらしさを0~1の小数で返す)でエッジを検出
- 検出したエッジに対してHough変換で直線を検出
- 得られた直線から構成可能な四角形の候補をリストアップ
- DNNの出力(0~1の実数)を四角形の辺に沿って平均してスコアとする。
- スコアの最も高かった四角形を、紙の領域として提案
というような感じでした。
ただ肝心な「何からの深層学習の方法」ということが示されていなかったので適当にCNNを使ったエッジ検出方法を見ていたら何個か見つかりました。
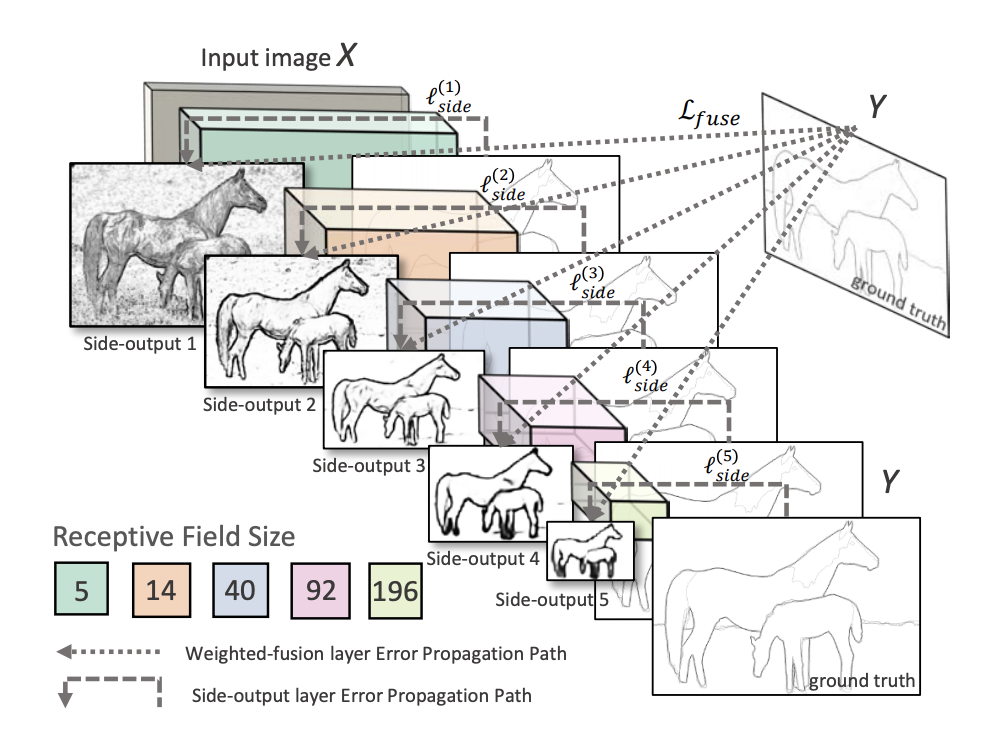
HED(Hostically-Nested Edge Detection)
画像をCNNで畳み込んで行き、各レイヤーの出力をSide Layerと呼ばれる層で逆畳み込みしてまとめて結合して出力という方法。
画像中に含まれるエッジのピクセルの数は非エッジのピクセルに比べて圧倒的に少ないので、エッジピクセルの数に応じて誤差関数を重み付けしたりエッジ検出に特化した工夫がなされている。
詳細は参考URLを見てください。この手法のメリットはVGG16を転移学習して使うので学習コストが軽い点だと思います。
逆にデメリットはネットワークの構造的に画像の情報を余り深く理解できていなさそうなとこ。
ただ紙の認識では雑に紙のエッジを検出してくれれば大丈夫なので、そんなデメリットは気にしなくていい気もします。
高みを目指したい人はネットワークの構造をM2DetみたいにPyramid構造とかに変更したら精度あがるんじゃないかと思う。
画像は論文からの引用。
CASENet
HEDは画像の各ピクセル。HEDは二値分類問題を前提としているので、複数種類の矩形物体を検知したい場合にはこちらを検討することになると思います。
自分では試してないので何とも得いませんが、論文を読む感じ基本的なネットワークのコンセプトはHEDに近しいものを感じます(当然細部は全く異っていますが)。
HEDは2015年、CASENetは2017年の論文なので最新の論文を漁ればもっと良さげな手法もあるかと思いますが、とりあえず紙を検出するくらいであれば、この辺の手法で行けるのではと思います(CASENetの方は試してないので何とも言えませんが)。
試してみた
HEDの中間層を適当に変えたり出力層のチャネル数変えたり色々改造したもの(細かい条件は忘れた)を使って実際の紙を認識できるか試してみました。
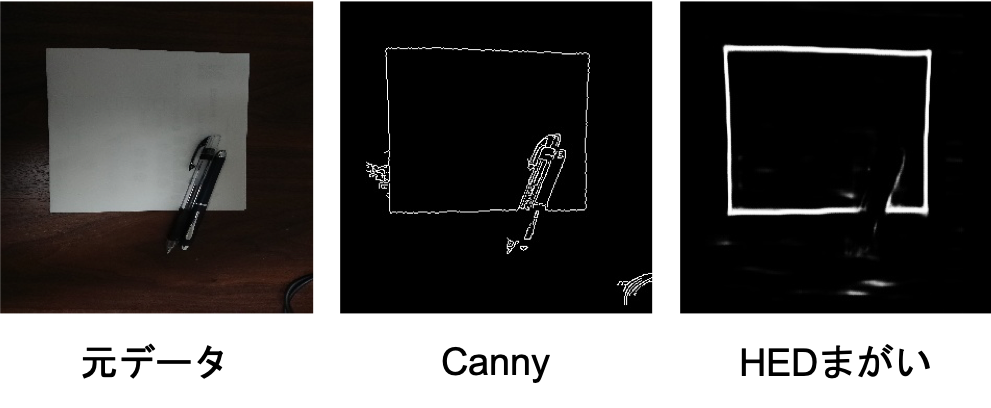
Cannyは紙だけでなくペンのエッジも拾ってるのがわかります。
一方、HED使って予測したものはペンのエッジは検出されず、紙の輪郭だけをしっかり拾っているのが確認できます(ペンの部分を補完することはできていませんが)。今回はシンプルな画像で試しましたが色々写り込んでいてCannyでうまくエッジの矩形の検出ができないときは、深層学習+Hough変換でもいいかもねっていう記事でした。